Naive Bayes Classifier - Movie Review Analysis
A Naive Bayes classifier is a probabilistic machine learning model that’s used for classification tasks. The crux of the classifier is based on the Bayes theorem.
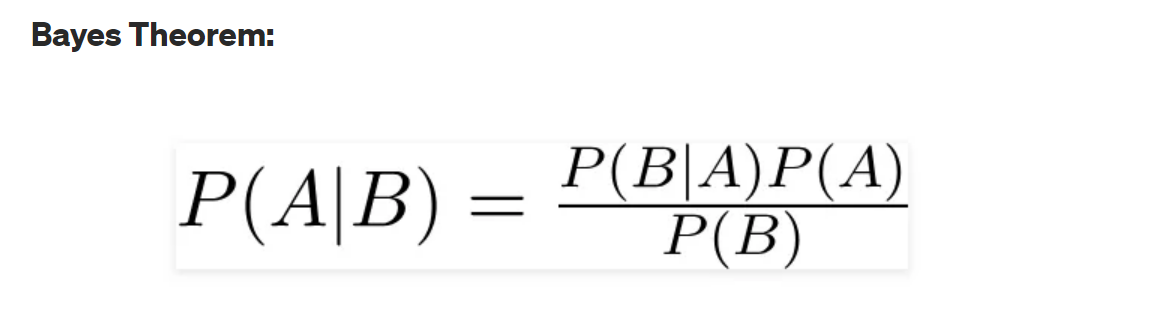
Bayes theorem is used to find the probability of A happening, given that B has occurred. In this case, B is the evidence and A is the hypothesis. The assumption made here is that the predictors or features are independent, meaning the presence of one particular feature does not affect the other. Because of this assumption, the classifier is called naive.
Programming Steps
Firstly, we will read a CSV file named 'rt_reviews' with encoding parameter iso-8859-1
import pandas as pd
df_reviews=pd.read_csv("rt_reviews.csv",encoding="iso-8859-1")
df_reviews.head(5)
I have split the dataset into three different set that is Train, test and validation sets
[1]
df_reviews = df_reviews.sample(frac=1)
total_rows = df_reviews.shape[0]
train_size = int(total_rows*0.80)
# Spliting data into test and train
train = df_reviews[0:train_size]
test_set = df_reviews[train_size:]
# train into train set and validation set
train= train.sample(frac=1)
train_size = int(0.8*len(train))
train_set = train[:train_size]
val_set = train[train_size:]
I have implemented a basic pre-processing step for text data that removes punctuation and converts all text to lowercase, which can help to normalize the data and make it easier to analyze or model.
[2]
def textProcessing(text):
text=text.str.replace('\W', ' ') # to remove punctuations from string
return text.str.lower() #to convert string into lowercase format
train_set['Review']=textProcessing(train_set['Review'])
train_set.head()
I have created a vocabulary list of words from Review column by spliting the sentence for every whitespace and then I have used the set function to eleminate the dublicates, thus by end of the process we will get unique vocabuary list.
[2]
train_set['Review'] = train_set['Review'].astype(str).str.split()
vocabulary = []
for review in train_set['Review']:
for word in review:
vocabulary.append(word)
vocabulary = list(set(vocabulary))
len(vocabulary)
I have initialized a sparse matrix with dimensions equal to the number of reviews in the training set and the number of unique words in the vocabulary list. The code iterates over each review in the training set and each word in the review, finds the index of the word in the vocabulary list, and updates the corresponding entry in the sparse matrix with a count of 1.
from scipy.sparse import lil_matrix
# Initializing the sparse matrix of shape num_reviews x num_words
word_counts = lil_matrix((len(train_set['Review']), len(vocabulary)), dtype=int)
# Updating the word counts for each review from training set
for index, review in enumerate(train_set['Review']):
for word in review:
word_index = vocabulary.index(word)
word_counts[index, word_index] += 1
The sparse matrix is converted into pandas DataFrame for analysing and modeling
# Converting the sparse matrix to a DataFrame
word_counts_df = pd.DataFrame(word_counts.todense(), columns=vocabulary)
# Adding the Review and Freshness columns
word_counts_df['Review'] = train_set['Review']
word_counts_df['Freshness'] = train_set['Freshness']
cols = list(word_counts_df.columns)
cols.remove('Review')
cols.remove('Freshness')
word_counts_df = word_counts_df[['Review', 'Freshness'] + cols]
word_counts_df.head()
Now, the rotten and fresh reviews are isolated from the DataFrame of word counts. The probability of a review being rotten or fresh is calculated by dividing the length of the corresponding DataFrame by the total number of reviews in the original DataFrame. The code then calculates the total number of words in all the rotten and fresh reviews by summing the length of each review in the corresponding DataFrame, and also calculates the total number of unique words in the vocabulary list. Finally, the value of the smoothing parameter 'alpha' is set to 1, which is used in Laplace smoothing to address the issue of zero probabilities in probabilistic models by adding a small constant to each count.
[2]
# Isolating rotten and fresh review
rotten_review = word_counts_df[word_counts_df['Freshness'] == 'rotten']
fresh_review = word_counts_df[word_counts_df['Freshness'] == 'fresh']
# P(rotten) and P(fresh)
p_rotten = len(rotten_review) / len(word_counts_df)
p_fresh = len(fresh_review) / len(word_counts_df)
# N_rotten
n_words_per_rotten_review = rotten_review['Review'].apply(len)
n_rotten = n_words_per_rotten_review.sum()
# N_fresh
n_words_per_fresh_review = fresh_review['Review'].apply(len)
n_fresh = n_words_per_fresh_review.sum()
# N_Vocabulary
n_vocabulary = len(vocabulary)
# Laplace smoothing
alpha = 1
I have initialized two dictionaries to store the probabilities of each word given a review being rotten or fresh. The probabilities are calculated for each unique word in the vocabulary by summing the count of each word in the corresponding rotten or fresh reviews and applying Laplace smoothing. The value of alpha is added to the count of each word to address the issue of zero probabilities. The Laplace smoothed probability of each word given a review being rotten or fresh is then stored in the corresponding dictionary.
[2]
# Initiate parameters
parameters_rotten = {unique_word:0 for unique_word in vocabulary}
parameters_fresh = {unique_word:0 for unique_word in vocabulary}
# Calculate parameters
for word in vocabulary:
n_word_given_rotten = rotten_review[word].sum()
p_word_given_rotten = (n_word_given_rotten + alpha) / (n_rotten + alpha*n_vocabulary)
parameters_rotten[word] = p_word_given_rotten
n_word_given_fresh = fresh_review[word].sum()
p_word_given_fresh = (n_word_given_fresh + alpha) / (n_fresh + alpha*n_vocabulary)
parameters_fresh[word] = p_word_given_fresh
I have defined a function called "classify_test_set" which preprocesses the input string by replacing non-word characters with a space, converting the string to lowercase, and splitting it into individual words. It then calculates the probability of the input string being classified as a "rotten" or "fresh" review by multiplying the prior probability of each class with the conditional probability of each word in the input string given the respective class. The function then prints the probabilities of the input string belonging to each class and returns the class with the higher probability. If the probabilities of both classes are equal, it returns a message to have a human classify the review.
[2]
import re
def classify_test_set(review):
'''
review: a string
'''
review = re.sub('\W', ' ', review)
review = review.lower().split()
p_rotten_given_review = p_rotten
p_fresh_given_review = p_fresh
for word in review:
if word in parameters_rotten:
p_rotten_given_review *= parameters_rotten[word]
if word in parameters_fresh:
p_fresh_given_review *= parameters_fresh[word]
print('P(rotten|review):', p_rotten_given_review)
print('P(fresh|review):', p_fresh_given_review)
if p_fresh_given_review > p_rotten_given_review:
return 'fresh'
elif p_fresh_given_review < p_rotten_given_review:
return 'rotten'
else:
return 'Equal proabilities, have a human classify this!'
I have created predicted column which stores the Freshness of the movie review based on the above function classify_test_set.
[2]
test_set['predicted'] = test_set['Review'].apply(classify_test_set)
test_set.head()
The total number of reviews in the test set is stored in the 'total' variable. Finally, the code prints the number of correct and incorrect predictions, as well as the accuracy of the model, which is the proportion of correct predictions out of the total number of reviews.
[2]
correct = 0
total = test_set.shape[0]
for row in test_set.iterrows():
row = row[1]
if row['Freshness'] == row['predicted']:
correct += 1
print('Correct:', correct)
print('Incorrect:', total - correct)
print('Accuracy:', correct/total)
I have divided the dataset into training, validation, and testing sets. The df_reviews DataFrame was first shuffled, then 80% of the data was used for training and the remaining 20% for testing. The training set was further split into 80% for training and 20% for validation. This allowed for the model to be trained on one part of the data and tested on another to evaluate its performance.
I have preprocessed the review column by removing the punctuations and converted the string in lowercase format which helped to normalize the dataset and makes it easier to analyze and model the data. I have implemented sparse matrix to overcome Memory Error, here the vocabulary list with index is saved into the matrix. Implemented Smoothing concept to avoid probabilities of zero values affecting the entire model probability calculations.
I have implemented the model with different training and validation sizes. Apart from changing the size of the model (version2), I have implemented version 3 of the jupiter notebook where I have used stemming and lemmatization. You can find all the three versions of the classifier implemetation in my github repository.

import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer, PorterStemmer
lemmatizer = WordNetLemmatizer()
stemmer = PorterStemmer()
stop_words = set(stopwords.words('english'))
punctuations = set(string.punctuation)
vocabulary = []
for review in train_set['Review'].astype(str):
words = review.lower().split()
# we will remove stop words, punctuation, and words with length < 3
filtered_words = [word for word in words if word not in stop_words
and word not in punctuations and len(word) >= 3]
# Lemmatize and stem each word
lemmatized_words = [lemmatizer.lemmatize(word) for word in filtered_words]
stemmed_words = [stemmer.stem(word) for word in lemmatized_words]
# Add remaining words to vocabulary list
vocabulary.extend(stemmed_words)
# we will remove duplicate words from vocabulary list
vocabulary = list(set(vocabulary))
print(len(vocabulary))
References
[1]https://www.geeksforgeeks.org/how-to-split-data-into-training-and-testing-in-python-without-sklearn/
[2]https://www.kdnuggets.com/2020/07/spam-filter-python-naive-bayes-scratch.html
[3]https://www.enjoyalgorithms.com/blog/sentiment-analysis-using-naive-bayes